数据结构与算法分析期末笔寄

绪论
软件
-
软件的定义:
- 定义1: 能够对人们提供帮助的、能够在计算机上运行的程序都可以称 为软件
- 定义2:
- 更准确 利用计算机本身提供的逻辑功能,合理地组织计算机的工作流 程,简化或替代人们使用计算机过程中的各个环节,提供给使 用者一个便于操作的工作环境的“程序集”。
- 软件包括计算机程序和与之相关的文档资料的总和(文档是指编制程序所使用的技术资料和使用该程序的说明性资料,如使用说明书等,即开发、使用和维护程序所需的一切资料 )
-
软件生存期:指从软件项目的需求定义到完成使命后而废弃的全过程
-
软件工作阶段:制定计划、需求分析和定义、软件设计、程序编制、软件测试、运行/维护
-
软件程序设计主要环节:明确需求、涉及、编码、测试
数据结构
-
基本概念
- 数据:描述客观事物的数、字符以及所有能输入到计算机中并被计算机程序处理的符号的集合。具有可识别性、可加工处理性和可存储性等特征。
- 数据元素:数据的基本单位,即数据这个集合中的一个个体(客体)。一个数据元素可由若干个数据项组成。
- 数据项:数据的最小单位
- 数据对象:具有相同特性的数据元素的集合
-
数据结构
-
定义:按某种逻辑关系组织起来的一批数据,应用计算机语言,按一定的存储表示方式把他们存储在计算机的存储器,并在这些数据上定义了一个运算的集合。
-
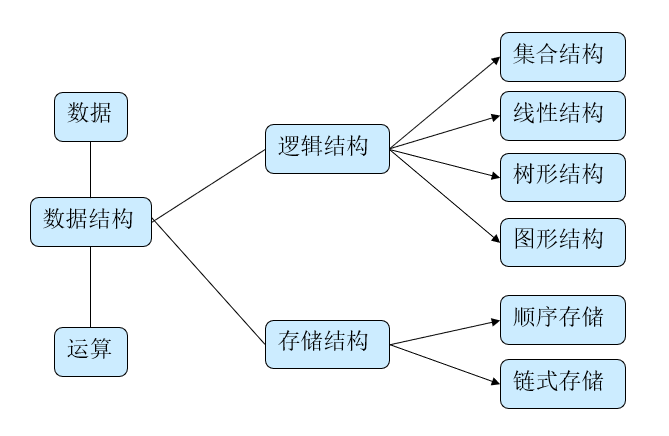
主要内容:
-
逻辑结构:数据元素间的逻辑关系
- 线性结构:有且仅有一个开始结点和一个终端结点,且所有结点都最多只有一个直接前趋和一个直接后继
- 非线性结构:非线性结构的逻辑特征是一个结点可能有多个直接前趋和直接后继
-
存储结构:数据元素及其关系在计算机存储器内的表示(顺序存储、链式存储、哈希存储)
-
顺序存贮方法
该方法是把逻辑上相邻的结点存贮在物理位置上相邻的存贮单元里,结点间的逻辑关系由存贮单元的邻接关系来体现。由此得到的存贮表示称为顺序存贮结构。(该方法主要应用于线性的数据结构,非线性的数据结构)
-
链接存贮方法
该方法不要求逻辑上相邻的结点在物理位置上亦相邻,结点间的逻辑关系是由附加的指针字段表示的。由此得到的存贮表示称为链式存贮结构
-
索引存贮方法
该方法建立附加的索引表指示数据的存储位置。索引表中的每一项称为索引项,一般形式是: 关键字,是能惟一标识一个结点或一组结点的那些数据项;地址,是存储数据的位置
-
散列存贮方法
该方法的基本思想是根据结点的关键字直接计算出该结点的存贮地址
Address=H(KeyWord)
-
-
对数据施加的操作:数据的运算
-
-
算法
-
性质:
- 输入性:具有零个或多个输入量,即算法开始前对算 法给出的初始量;
- 输出性:至少产生一个输出;
- 有穷性:每条指令的执行次数必须是有限的;
- 确定性:每条指令的含义必须明确,无二义性;
- 可行性:每条指令都应在有限的时间内完成。
-
程序和算法的区别:
一个程序不一定满足有穷性。
- 可运行性:程序中的指令必须是机器可执行的,而算法中的指令则无此限制
- 两者关系:算法若用机器可执行的语言来书写,则它就是一个程序
-
复杂性:
算法复杂性的高低体现在运行该算法所需要的计算机资源(时间和空间)的多少上,所需要的资源越多,算法的复杂性越高,反之亦然。
- 算法的时间复杂性是指算法所需时间资源的量。
- 算法的空间复杂性是指算法所需空间资源的量。
定义:如果存在正常数和使得当时,则记为
定义:如果存在正常数和使得当时,则记为
定义:当且仅当且时,
定义:如果且,则
法则1:如果且,那么
法则2:如果是一个次多项式,则
法则3:对于任意常数,
线性数据结构
- 定义:线性表是由个数据元素构成的有限序列。其中,数据元素的个数n定义为表的长度。当时称为空表,通常将非空的线性表记作:。
- 性质:
- 同一线性表中的元素必定具有相同的特性
- 对于非空的线性表,有且仅有一个开始结点 ,有且仅有一个终端结点
- 当时,有且仅有一个直接后继 ;当时,有且仅有一个直接前趋
- 线性表中结点之间的逻辑关系即是上述的邻接关系;
- 线性表是一个线性结构。
顺序表
-
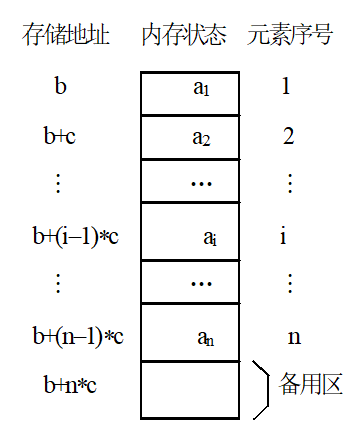
定义:线性表的顺序存储结构,是用一组地址连续的存储单元依次存储线性表的元素
-
性质:
-
线性表的第个元素的存储位置为
-
起始位置或基地址:
-
线性表的这种机内表示称做线性表的顺序存储结构或顺序映象
-
线性表的顺序存储结构是一种随机存取的存储结构
-
-
特点:
- 优点:随机存取表中任意元素;存储位置可用一个简单直观的公式表示;存储密度高
- 缺点:在做插入或删除运算时,需移动大量元素;线性表按最大空间预先分配;表的容量难以扩充
#include<bits/stdc++.h>
#define MAXN 1005
using namespace std;
typedef struct sequenlist{
char list[MAXN];
int cnt;
}sequenlist;
sequenlist *create(){
sequenlist *list=(sequenlist*)malloc(sizeof(sequenlist));
list->cnt=-1;
cout<<"Input the list:";
cin>>list->list;
list->cnt=strlen(list->list);
return list;
}
void insert(sequenlist *list, int idx, char data){
if(idx>MAXN){
cout<<"[Insert Error] Overflow Detected\n";
return;
}
if((idx<1) || (idx>list->cnt+1)){
cout<<"[Insert Error] Illegal Index\n";
return;
}
// 元素后移
strcpy(list->list+idx, list->list+idx-1);
// 插入元素
list->list[idx-1]=data;
list->cnt++;
return;
}
void del(sequenlist *list, int idx){
if(idx>MAXN){
cout<<"[Delete Error] Overflow Detected\n";
return;
}
if((idx<1) || (idx>list->cnt)){
cout<<"[Delete Error] Illegal Index\n";
return;
}
strcpy(list->list+idx-1, list->list+idx);
list->list[--list->cnt]=0;
}
char get(sequenlist *list, int idx){
if(idx>MAXN){
cout<<"[Get Error] Overflow Detected\n";
return -1;
}
if((idx<1) || (idx>list->cnt)){
cout<<"[Get Error] Illegal Index\n";
return -1;
}
return list->list[idx];
}
void show(sequenlist *list){
if(list->cnt==0){
cout<<"[Warning] The list is empty\n";
}
for(int i=0;i<list->cnt;i++)
cout<<list->list[i]<<" ";
cout<<"\n";
}
int main(){
sequenlist *list;
list = create();
// 插入元素
cout<<"请输入要插入的位置和元素:";
while(1){
int idx;
char inp;
cin>>idx;
del(list, idx);
show(list);
}
}
链式存储结构
- 概念:
- 链表是用一组任意的存储单元来存放线性表的元素,这组存储单元既可以是连续的,也可以是不连续的
- 存储数据元素信息的域称作数据域;存储后继元素存储位置的域称作指针域,指针域中存储的信息称指针或链。
- 单链表
- 概念:链表的每个结点中只包含一个指针域,故将这种链表称为单链表。
- 循环链表
- 概念:循环链表是表中最后一结点的指针域指向头结点,整个链表形成一个环
- 特点:
- 从表中任意结点出发均可找到表中其它结点
- 判别链表中最后一个结点的条件不再是**"后继是否为空",而是"后继是否为头结点"**
- 双链表
- 概念:在双向链表的结点中有两个指针域,其一指向直接后继,另一指向直接前趋
线性数据结构的选择
存储空间:
- 顺序存储结构是静态分配,造成浪费和空间溢出;
- 链式存储结构是动态分配,不会发生空间溢出。
- 存储密度:存储密度越大,存储空间的利用率就越高。显然,顺序存储结构的存储密度为1,而链式存储结构的存储密度小于1。 (存储密度=数据所需空间/使用数据结构所需空间)
运算时间:
查改操作多、增删操作少时,采用顺序存贮结构;查改操作多、增删操作少时,采用链式存储结构。
顺序存储结构是一种随机存取结构;链式存储结构不是随机存取结构
顺序表的插入和删除需移动大量元素;链表的插入或删除,只要修改相应的指针及进行一定的查找
栈
-
定义:
- 栈是限定仅在表尾进行插入和删除运算的线性表;
- 表尾称为栈顶(Top);
- 表头称为栈底(Bottom);
- 当栈中没有数据元素时称为空栈。
-
特性:对于栈来说,最后进栈的数据元素,最先出栈,故把栈称为**后进先出(
LIFO-Last In First Out)的数据结构,或先进后出(FILO-First In Last Out)**的数据结构 -
代码:
- 自己实现:
// 自己实现栈数据结构 #include<bits/stdc++.h> #define MAXN 1005 using namespace std; typedef struct Stack{ char data[MAXN]; int sp; }Stack; Stack* SetNull(){ Stack *st=(Stack*)calloc(sizeof(Stack), 1); return st; } bool Empty(Stack *st){ return st->sp==0?1:0; } char GetTop(Stack *st){ if(Empty(st)){ cout<<"[GetTop Error] The stack is empty\n"; return 0; } return st->data[st->sp-1]; } void push(Stack* st, char inp){ if(st->sp>MAXN){ cout<<"[Push Error] Overflow Detected\n"; return; } st->data[st->sp++] = inp; } char pop(Stack* st){ if(IsEmpty(st)){ cout<<"[Pop Error] The stack is empty\n"; return 0; } return st->data[st->sp--]; } int main(){ Stack* st=SetNull(); }-
STL:
#include<stack> using namespace std; int main(){ //stack<DataType> VariableName; stack<char> st; st.top(); //返回一个栈顶元素的引用,类型为 T&。如果栈为空,返回值未定义。 st.push(const T& obj); //可以将对象副本压入栈顶。这是通过调用底层容器的 push_back() 函数完成的。 st.push(T&& obj); //以移动对象的方式将对象压入栈顶。这是通过调用底层容器的有右值引用参数的 push_back() 函数完成的。 st.pop(); //弹出栈顶元素。 st.size(); //返回栈中元素的个数。 st.empty(); //在栈中没有元素的情况下返回 true。 st.swap(stack<T> & other_stack); //将当前栈中的元素和参数中的元素交换。参数所包含元素的类型必须和当前栈的相同。对于 stack 对象有一个特例化的全局函数 swap() 可以使用。 }
队列
-
定义:队列也是一种运算受限的线性表。
- 它只允许在表的一端进行插入,该端称为队尾(Rear)
- 它只允许在表的另一端进行删除,该端称为队头(Front)。
- 队列亦称作先进先出(First In First Out)的线性表。
- 当队列中没有元素时称为空队列
-
特性:对于栈来说,先进队列的数据元素,后出队列,故把栈称为**先进先出(
LIFO-First In First Out)**的数据结构 -
代码:
-
自己实现:
#include<bits/stdc++.h> #define MAXN 1005 using namespace std; typedef struct Queue{ char data[MAXN]; int frt, rear; }Queue; Queue* SetNull(){ Queue *queue = (Queue*)calloc(sizeof(Queue), 1); queue->frt = MAXN-1; queue->rear = MAXN-1; return queue; } bool Empty(Queue* queue){ return queue.frt==queue.rear?1:0; } void Front(Queue* queue){ if(Empty(queue)){ cout<<"[Front Error] The queue is empty\n"; return; } return queue->data[queue->frt-1]; } void Enqueue(Queue* queue, char inp){ if((queue->rear-1+MAXN)%MAXN==queue->frt){ cout<<"[Enqueue Error] The queue is full\n"; return; } queue->rear=(queue->rear-1+MAXN)%MAXN; queue->data[queue->rear]=inp; } char Dequeue(Queue* queue){ if(Empty(queue)){ cout<<"[Dequeue Error] The queue is empty\n"; return 0; } queue->frt=(queue->frt-1+MAXN)%MAXN; return queue->data[queue->frt]; } int main(){ Queue* queue = SetNull(); } -
STL:
#include<queue> using namespace std; int main(){ //queue<DataType> VariableName; queue<char> qu; qu.front(); //返回 queue 中第一个元素的引用。如果 queue 是常量,就返回一个常引用;如果 queue 为空,返回值是未定义的。 qu.back(); //返回 queue 中最后一个元素的引用。如果 queue 是常量,就返回一个常引用;如果 queue 为空,返回值是未定义的。 qu.push(const T& obj); //在 queue 的尾部添加一个元素的副本。这是通过调用底层容器的成员函数 push_back() 来完成的。 qu.push(T&& obj); //以移动的方式在 queue 的尾部添加元素。这是通过调用底层容器的具有右值引用参数的成员函数 push_back() 来完成的。 qu.pop(); //删除 queue 中的第一个元素。 qu.size(); //返回 queue 中元素的个数。 qu.empty(); //如果 queue 中没有元素的话,返回 true。 qu.emplace(); //用传给 emplace() 的参数调用 T 的构造函数,在 queue 的尾部生成对象。 qu.swap(queue<T> &other_q); //将当前 queue 中的元素和参数 queue 中的元素交换。它们需要包含相同类型的元素。也可以调用全局函数模板 swap() 来完成同样的操作。 }
-
串
-
定义:一种特殊的线性表,它的数据元素仅由一个字符组成
- 串(String)是由零个或多个字符组成的有限序列。一般记为 S=“a1a2…an”,其中S是串名,用两个双引号括起的字符序列是串值;ai可以是字母、数字或其它字符;串中所包含的字符个数称为该串的长度。长度为零的串称为空串,它不包含任何字符
- 串中任意个连续的字符组成的子序列称为该串的子串。包含子串的串称为主串。
- 子串的第一个字符在主串中的序号,定义为子串在主串中的位置(或序号)。特别地,空串是任意串的子串,任意串是其自身的子串。
-
基本操作:
#include<string> #include<bits/stdc++.h> using namespace std; int main(){ string r, s, t; //赋值 s="abcdefghijk"; t="0123456789"; //连接 r = s+t; cout<<r<<endl; //求串长 int length = r.length(); int size = r.size(); cout<< length<<" "<<size<<endl; //求子串 s = r.substr(0, 8); cout<<s<<endl; //比较串大小 int rel = strcmp(s.data(), t.data()); cout<<rel<<endl; //插入 s = r.insert(8, r); cout<<s<<endl; //删除 s = r.erase(8, 4); cout<<s<<endl; //查找 const char* rst = r.data(); const char* dst = t.data(); char* idx = strstr(rst, dst); cout<<idx-rst<<endl; //替换 s = r.replace(1, 5, "abcde"); cout<<s<<endl; } -
模式匹配
-
布鲁特——福斯(
Brute force)算法:#include<bits/stdc++.h> #define MAXN 1005 using namespace std; int index(char *s, char *t){ for(int i=0;i<strlen(s)-strlen(t);i++){ for(int j=0;j<strlen(t);j++) if(s[i+j]!=t[j]) break; else if(j==strlen(t)-1) return i+1; } return -1; } int main(){ char s[MAXN], t[MAXN]; cin>>s>>t; cout<<index(s, t)+1; } -
KMP算法:
#include<bits/stdc++.h> #define MAXN 1005 using namespace std; char txt[MAXN], pat[MAXN]; int nex[MAXN+1]; void GenerateNext(){ int i=0, j=-1, len=strlen(pat); nex[0]=-1; while(i<len) if(j==-1 || pat[i]==pat[j]) nex[++i]=++j; else j = nex[j]; // for(int i=0;i<len;i++) // cout<<nex[i]<<" "; // cout<<"\n"; } int KMP(){ int len_txt=strlen(txt), len_pat=strlen(pat); int i=0, j=0; while(i<len_txt && j<len_pat) if(j==-1||txt[i]==pat[j]) i++, j++; else j=nex[j]; if(j==len_pat) return i-j+1; return -1; } int main(){ cout<<"Input the main string: "; cin>>txt; cout<<"Input the pattern string: "; cin>>pat; GenerateNext(); int idx = KMP(); cout<<idx; }
-
数组
-
概念:数组是由值与下标构成的有序对,结构中的每一个数据元素都与其下标有关
-
性质:
- 数据元素数目固定:一旦说明了一个数组结构,其元素数目不再有增减变化
- 数据元素具有相同的类型
- 数据元素的下标关系具有上下界的约束并且下标有序
-
基本操作:
- 给定一组下标,存取相应的数据元素
- 给定一组下标,修改相应数据元素中的某个数据项的值。
-
地址运算:
或者
稀疏矩阵
- 定义:-含有非零元素及较多的零元素,但非零元素的分布没有任何规律,这种矩阵称为稀疏矩阵。即稀疏矩阵中有个非零元素,个零元素,若,则称为稀疏矩阵
- 三元组:
- 将稀疏矩阵的非零元素用三元组按行优先(或列优先)的顺序排列(跳过零元素),则得到一个其结点均是三元组的线性表
非线性数据结构
树
-
定义:
- 树是一种按层次关系组织起来的分支结构。
- 递归定义:树(Tree)是(≥0)个结点的有限集合T,满足两个条件:
- 有且仅有一个特定的称为根(Root)的结点,它没有前趋;
- 其余的结点可分成m个互不相交的有限集合,其中每个集合又是一棵树,并称为根的子树。
- 当=0时的空集合定义为空树
-
相关概念:
- 结点:指树中的一个元素,包含数据项及若干指向其子树的分支。
- 结点的度:指结点拥有的子树个数。
- 树的度:指树中最大结点度数。
- 叶子:指度为零的结点,又称为终端结点。
- 孩子:一个结点的子树的根称为该结点的孩子。
- 双亲:一个结点的直接上层结点称为该结点的双亲。
- 兄弟:同一双亲的孩子互称为兄弟
- 结点的层次:从根结点开始,根结点为第一层,根的孩子为第二层,根的孩子的孩子为第三层,依次类推。
- 树的深度:树中结点的最大层次数。
- 堂兄弟:双亲在同一层上的结点互称为堂兄弟。如图中一系1室和二系1室互为堂兄弟
- 路径:若存在一个结点序列,可使到达,则称这个结点序列是到达的一条路径。
- 子孙和祖先:若存在到的一条路径,则为的祖先,而为的子孙。图中学校和各系是教研室的祖先,而系和教研室是学校的子孙。
- 森林:棵互不相交的树的集合构成森林。删除一棵树的根时,就得到了子树构成的森林,当在森林中加上一个根结点时,则森林就变为一棵树。
- 有序树和无序树:若将树中每个结点的各个子树都看成是从左到右有次序的(即不能互换),则称该树为有序树,否则为无序树。
-
树的存储:
-
顺序存储:顺序存储时,首先必须对树形结构的结点进行某种方式的线性化,使之成为一个线性序列,然后存储。
-
双亲表示法:
typedef struct{ datatype data; /* 数据域 */ int parent ; /* 双亲结点的下标 */ }ptree; ptree T[maxsize]; -
孩子(双亲)表示法:
typedef struct child{ int idx; child* next; }child; typedef struct node{ DataType data; int parent; //(双亲) child *children; }node; node tree[MAXN]; -
孩子兄弟表示法:
typedef struct node{ DataType data; node* FirstChild, *Bro; }node; -
可以通过构造”虚节点“将二叉树映射为完全二叉树,来保证逻辑关系,但是存在空间浪费
-
-
链式存储:链式存储时,使用多指针域的结点形式,每一个指针域指向一棵子树的根结点。
-
-
转换:
-
树转换为二叉树:
- 在兄弟(非堂兄弟)之间增加一条连线;
- 对每个结点,除了保留与其左孩子的连线外,除去与其它孩子之间的连线;
- 以树的根结点为轴心,将整个树顺时针旋转45度。
-
二叉树转换成树
- 若结点X是双亲Y的左孩子,则把X的右孩子,右孩子的右孩子…都与Y用连线相连。
- 去掉原有的双亲到右孩子的连线。
-
森林转换成二叉树
- 先将森林中的每一棵树转换为二叉树
- 再将第一棵树的根作为转换后二叉树的根,第一棵树的左子树作为转换后二叉树根的左子树
- 第二棵树作为转换后二叉树的右子树,第三棵树作为转换后的二叉树根的右子树的右子树,如此类推下去。
-
二叉树
-
定义:二叉树是个结点的有限集,它或为空树,或由一个根结点及两棵互不相交的、分别称作这个根的左子树和右子树的二叉树构成。
-
概念:
- 满二叉树:一棵深度为k且有个结点的二叉树称为满二叉树。( 满二叉树的特点是每一层的结点数都达到该层可具有的最大结点数。不存在度数为1的结点。)
- 完全二叉树:如果一个深度为k的二叉树,它的结点按照从根结点开始,自上而下,从左至右进行连续编号后,得到的顺序与满二叉树相应结点编号顺序一致,则称这个二叉树为完全二叉树。
-
性质:
- 二叉树是有序树
- 在二叉树的第层上至多有个结点
- 深度为的二叉树至多有个结点
- 对任何一棵二叉树,如果其终端结点(叶子节点)数为,度为2的结点数为,则
- 具有个结点的完全二叉树的深度为或
-
存储:
-
顺序存储:
将二叉树从上至下,从左至右编号,将编号映射为顺序表下表
- 若,则i结点是根结点;
- 若,则结点的双亲编号为。
- 若,则是结点的左孩子,否则结点无左孩子,结点是终端结点(叶子节点);
- 若,则是结点i的右孩子,否则结点无右孩子
- 若为奇数且不等于1时,结点的左兄弟是,否则结点没有左兄弟。
- 若为偶数且小于时,结点的右兄弟是结点,否则结点没有右兄弟。

tydef struct{ DataType data[MAXN]; int last;//The id of the last point }BitreeInList; -
链式存储:
-
二叉链表
含有两个指针域来分别指向左孩子指针域(lchild)和右孩子指针域(rchild),以及结点数据域(data),故二叉树的链式存储结构也称为二叉链表。
typedef struct{ DataType data; node *lchild, *rchild; }node; node* root; -
三叉链表
叉链表中,要寻找某结点的双亲是困难的,故增加一个指向其双亲的指针域parent
#include<bits/stdc++.h> using namespace std; typedef struct node{ char data; node *lchild, *rchild; }node; node* CreatBitreeInChain(){ char tmp=0; int cnt=0; node* root=NULL; queue<node*> q; while(cin.read(&tmp, 1) && tmp!=10){ node *s=NULL; cnt++; if(tmp!='@'){ s = (node*)malloc(sizeof(node)); s->data = tmp; s->lchild = s->rchild = NULL; } q.push(s); if(q.size()==1) root = s; else{ if(s && q.front()) if(cnt%2) q.front()->rchild = s; else q.front()->lchild = s; if(cnt%2) q.pop(); } } return root; } int main(){ node *root = CreatBitreeInChain(); printf("%p", root); } -
-
-
遍历:
-
深度优先
设以L、D和R分别表示遍历左子树、访问根结点和遍历右子树,并限定按先左后右进行遍历,则有三种遍历方案:
-
DLR( 先(前)序(根)遍历 )
void DLR(node *p){ if(p){ cout<<p->data; DLR(p->lchild); DLR(p->rchild); } } -
LDR ( 中序(根)遍历 )
//递归实现 void LDR(node *p){ if(p){ DLR(p->lchild); cout<<p->data; DLR(p->rchild); } } //非递归实现 void LDR(node *root){ stack<node*> st; node *p=root; while(!st.empty() || p){ while(p){ st.push(p); p = p->lchild; } cout<<st.top()->data; st.pop(); p = p->rchild; } } -
LRD ( 后序(根)遍历 )
void LRD(node *p){ if(p){ DLR(p->lchild); DLR(p->rchild); cout<<p->data; } } -
通过先序遍历和中序遍历还原树
node *BPI(string dlr, string ldr, int &idx){ if(!ldr.size()){ idx--; return NULL; } node *root = (node*)malloc(sizeof(node)); root->data = dlr[idx]; root->lchild = root->rchild = NULL; for(int i=0;i<ldr.size();i++){ if(ldr[i]==dlr[idx]){ idx++; root->lchild = BPI(dlr, ldr.substr(0, i), idx); idx++; root->rchild = BPI(dlr, ldr.substr(i+1, ldr.size()-i-1), idx); break; } } return root; }
-
-
广度优先
void BFS(node *root){ queue<node*> q; q.push(root); while(!q.empty()){ cout<<q.front()->data; if(q.front()->lchild) q.push(q.front()->lchild); if(q.front()->rchild) q.push(q.front()->rchild); q.pop(); } }
-
二叉排序树
-
定义:如果一棵二叉树的每个结点对应一个关键码,并且每个结点的左子树中所有结点的码值都小于该结点的关键码值,而右子树中所有结点的关键码值都大于该结点的关键码值,则这个二叉树称为排序二叉树。
-
性质:对二叉排序树进行中序遍历时,可以发现所得到的中序序列是一个递增有序序列。
-
操作:
-
插入节点:
//递归 node* insert(node* father, int val){ if(!father){ father = (node*)malloc(sizeof(node)); father->val = val; father->lchild = father->rchild = NULL; } else{ if(val<father->val) father->lchild = insert(father->lchild, val); else father->rchild = insert(father->rchild, val); } return father; } //循环 node* insert(node *root, int val){ node *s = (node*)malloc(sizeof(node)); s->lchild = s->rchild = NULL; s->val = val; if(!root) return s; node *p=root, *f=NULL; while(p){ f=p; if(s->val < p->val) p = p->lchild; else p = p->rchild; } if(val<f->val) f->lchild = s; else f->rchild = s; return root; } -
删除节点
这里课本和ppt有一说一讲得太烂了……网上看了一个:
- 情况1:删除的当前节点无左右孩子节点,那么就直接将当前要删除的节点设置为NULL即可。
- 情况2:删除的当前节点无左孩子节点,有右孩子节点,那么就将当前要删除的节点设置为右孩子节点即可。
- 情况3:删除的当前节点无右孩子节点,有左孩子节点,那么就将当前要删除的节点设置为左孩子节点即可。
- 情况4:删除的当前节点有右孩子节点也有左孩子节点,那么就选出右孩子树中最小的点,设置为当前要删除的节点即可。这种方式既可以保证二叉排序树的性质,由于右孩子树中最小的点,无左孩子节点(如果有左孩子节点,那么就不符合二叉树性质了)。
#include<bits/stdc++.h> using namespace std; typedef struct node{ int val; node *lchild, *rchild; }; node* insert(node *root, int val){ node *s = (node*)malloc(sizeof(node)); s->lchild = s->rchild = NULL; s->val = val; if(!root) return s; node *p=root, *f=NULL; while(p){ f=p; if(s->val < p->val) p = p->lchild; else p = p->rchild; } if(val<f->val) f->lchild = s; else f->rchild = s; return root; } node *Delete(node *root, int val){ node *p = root, *q = root; while(p){ if(p->val==val) break; q = p; if(val<p->val) p = p->lchild; else if(val>p->val) p = p->rchild; } if(!p->lchild && !p->rchild){ if(p == q){ free(p); return NULL; } q->lchild==p?q->lchild=NULL:q->rchild=NULL; } else if(!p->lchild){ if(p==q){ node *tmp = p->rchild; free(p); return tmp; } q->lchild==p?q->lchild=p->rchild:q->rchild=p->rchild; } else if(!p->rchild){ if(p==q){ node *tmp = p->lchild; free(p); return tmp; } q->lchild==p?q->lchild=p->lchild:q->rchild=p->lchild; } else{ node *f=p->rchild, *g = p; while(f->lchild){ g = f; f = f->lchild; } if(g!=p) g->lchild = f->rchild; f->lchild = p->lchild; if(f != p->rchild) f->rchild = p->rchild; if(p == root){ free(p); return f; } q->lchild==p?q->lchild=f:q->rchild=f; } return root; } void inorder(node *father){ if(father){ inorder(father->lchild); cout<<father->val<<" "; inorder(father->rchild); } } int main(){ int n; cin>>n; node *root=NULL; for(int i=0;i<n;i++){ int tmp; cin>>tmp; root = insert(root, tmp); } root = Delete(root, 5); inorder(root); }
-
哈夫曼树
-
定义及相关概念:
-
若树中的两个结点之间存一条路径,则路径的长度是指路径所经过的边(即连接两个结点的线段)的数目。
-
树的路径长度是树根到树中每一结点的路径长度之和。
-
树的带权路径长度为树中所有叶子结点的带权路径长度之和,记作:
其中为树中叶子结点的数目,为叶子结点i的权值,为叶子结点到根结点之间的路径长度。
-
-
在有个带权叶子结点的所有二叉树中,带权路径长度最小的二叉树被称为最优二叉树或哈夫曼树。
-
-
性质:
- 哈夫曼树(最优二叉树)并不唯一
- 完全二叉树不一定是哈夫曼树(最优二叉树)
-
构造:
-
根据给定的个权值构成棵二叉树的集合, 其中中只有一个权值为的根结点,左、右子树均为空。
-
在中选取两棵根结点的权值为最小的树作为左、右子树构造一棵新的二叉树,且置新的二叉树的根结点的权值为左、右子树上根结点的权值之和。
-
在中删除这两个棵权值为最小的树,同时将新得到的二叉树加入中。
-
重复2、3直到中仅剩一棵树为止。这棵树就是哈夫曼树。
//链式存储实现哈夫曼树 #include<bits/stdc++.h> using namespace std; typedef struct node{ int val; bool ori; node *lchild, *rchild; }; struct cmp{ bool operator () (node* a, node* b){ return a->val > b->val; } }; priority_queue <node*, vector<node*>, cmp> q; int wpl=0; node* wrap(int val, bool ori, node* l, node* r){ node *father = (node*)malloc(sizeof(node)); father->val = val; father->ori = ori; father->lchild = l; father->rchild = r; return father; } void cal(int lev, node* father){ if(father == NULL) return; if(father->ori) wpl += (lev*father->val); cal(lev+1, father->lchild); cal(lev+1, father->rchild); } void debug(node *a, node *b){ cout<<"\n[Debug] "<<a->val<<" "<<b->val<<" [Debug]\n"; } int main(){ int n; cin>>n; for(int i=0;i<n;i++){ int tmp; cin>>tmp; q.push(wrap(tmp, 1, NULL, NULL)); } while(q.size()>1){ node *a, *b; a=q.top();q.pop(); b=q.top();q.pop(); // debug(a, b); q.push(wrap(a->val+b->val, 0, a, b)); } node *root = q.top(); cal(0, root); cout<<wpl; }
-
-
哈夫曼编码:
叶子tree[i]出发,利用双亲地址找到双亲结点tree[p],再利用tree[p]的lchild和rchild指针域判断tree[i]是tree[p]的左孩子还是右孩子,然后决定分配代码的 '0' 还是代码 '1' , 然后以tree[p]为出发点继续向上回潮,直到根结点为止。
#include <bits/stdc++.h> #define MAXN 1005 using namespace std; typedef struct node { int val; char data; node *lchild, *rchild; }; struct cmp { bool operator()(node *a, node *b) { return a->val > b->val; } }; priority_queue<node *, vector<node *>, cmp> q; map<char, std::string> key; int cnt[255]; int wpl = 0; node *wrap(int val, char data, node *l, node *r) { node *father = (node *)malloc(sizeof(node)); father->val = val; father->data = data; father->lchild = l; father->rchild = r; return father; } void cal(int lev, node *father) { if (father == NULL) return; if (!father->lchild) wpl += (lev * father->val); cal(lev + 1, father->lchild); cal(lev + 1, father->rchild); } void debug(node *a, node *b) { cout << "\n[Debug] " << a->val << " " << b->val << " [Debug]\n"; } void Encode(node *p, string path) { if (!p->lchild) { key[p->data] = path; return; } Encode(p->lchild, path + "0"); Encode(p->rchild, path + "1"); } void Decode(node *root) { char tmp; node *p = root; while (cin.read(&tmp, 1) && tmp != 10) { if (tmp == '0') p = p->lchild; else if (tmp == '1') p = p->rchild; else { cout << "[Input Error]"; return; } if (!p->lchild) { cout << p->data; p = root; } } } int main() { char inp[MAXN]; cin.getline(inp, 100); for (int i = 0; i < strlen(inp); i++) cnt[inp[i]]++; for (int i = 0; i < 255; i++) if (cnt[i] != 0) q.push(wrap(cnt[i], i, NULL, NULL)); while (q.size() > 1) { node *a, *b; a = q.top(); q.pop(); b = q.top(); q.pop(); q.push(wrap(a->val + b->val, 0, a, b)); } node *root = q.top(); cal(0, root); cout << "WPL: " << wpl << "\n"; Encode(root, ""); for (int i = 0; i < strlen(inp); i++) cout << key[inp[i]]; cout << "\n"; for (int i = 0; i < 255; i++) if (cnt[i] != 0) cout << char(i) << ": " << key[char(i)] << "\n"; Decode(root); }
图
-
定义:图(G)是一种非线性数据结构,它由两个集合和组成,形式上记为:,其中是顶点(Vertex)的非空有限集合,是中任意两个顶点之间的关系集合,又称为边(Edge)的有限集合
-
分类:
- 有向图:当且仅当图G的每条边有方向,有向边记为〈起始顶点,终止顶点〉
- 有向边又称为弧,因此弧的起始顶点就称为弧尾,终止顶点称为弧头。
- 顶点数n和边数e的无向图满足的关系。
- 完全无向图:的无向图
- 在有向图G中,若边则称为顶点邻接到或邻接于;并称边关联于顶点和或称边与顶点和相关联
- 在有向图中,把以顶点为终点的边的数目称为的入度,记为;把以顶点为起点的边的数目称为的出度,记为;把顶点的度定义为该顶点的入度和出度之和。
- 有向图中,若存在一个顶点v,从该顶点有路径可到达图中其它的所有顶点,则称这个有向图为有根图,v称为该图的根。
- 在有向图G中,若从到和从到都存在路径,则称和是强连通的。
- 若有向图V(G)中的任意两个顶点都是强连通的,则称该图为强连通图。有向图中的极大连通子图称作有向图的强连通分量。
- 无向图:G为无向图当且仅当G中的每条边是无方向的,记法:无向图用两个顶点组成的无序对表示,即(顶点1,顶点2)
- 无向图G中,若边则称顶点vi和vj相互邻接,互为邻接点;并称边关联于顶点和或称边与顶点和相关联
- 顶点数n和边数e的有向图满足的关系
- 完全有向图:的有向图
- 在无向图中关联于某一顶点的边的数目称为的度,记为。
- 无向图G中,若顶点和有路径相通,则称和是连通的。
- 稀疏图:的图
- 稠密图: 的图
- 子图:两个同类型的图和存在关系, 则称是的子图。
- 有向图:当且仅当图G的每条边有方向,有向边记为〈起始顶点,终止顶点〉
-
相关概念:
-
有n个顶点e条边的图G 中,每个顶点的度为,则存在以下关系:
-
权:如果图的边或弧具有一个与它相关的数时,这个数就称为该边或弧的权。
-
图中的每条边都具有权时,这个带权图被称为网络,简称为网。
-
若从顶点出发,沿着一些边经过顶点到达顶点,则称顶点序列为从到的一条路径。
- 若路径中的顶点不重复出现,则这条路径被称为简单路径。
- 对起点和终点相同并且路径长度≥2的简单路径被称为简单回路或者简单环。
-
-
图的存储:
-
顺序存储(邻接矩阵存储)
-
有向图:行和列中的非零元素个数分别对应于的顶点的出度和入度
-
无向图:行或列非零元素的个数对应于该顶点的度
typedef struct graph{ char vex[n]; double arcs[n][n]; }graph; void Creat(int n, int m){ for(int i=0;i<n;i++) cin>>graph.vex[i]; for(int i=0;i<m;i++){ int x, y, w; cin>>x>>y>>w; //无向图 w=1 graph.arcs[x][y] = graph.arcs[y][x] = w; //无向图 graph.arcs[x][y] = w; //有向图 } }
-
-
链式存储(邻接表存储)
void Creat(int n, int m){ for(int i=0;i<n;i++) cin>>ga[i].vex; for(int i=0;i<m;i++){ int x, y, w; cin>>x>>y>>w; //无向图 w=1 edgenode *s = (edgenode*)malloc(szieof(edgenode)); s->adjvex = y; s->value = w; s->next = ga[x].link; ga[x].link = s; edgenode *s = (edgenode*)malloc(szieof(edgenode)); s->adjvex = x; s->value = w; s->next = ga[y].link; ga[y].link = s; } } -
对比:
- 一个图的邻接矩阵表示是惟一的,而其邻接表表示不惟一
- 判定或是否是图中的一条边
- 在邻接矩阵表示中,只须判定矩阵中的第行第列的元素是否为零即可。
- 在邻接表中,则需要扫描vi对应的邻接链表,最坏的情况下需要时间。
- 求图中边的数目
- 使用邻接矩阵必须检测了整个矩阵才能确定,所消耗的时间为;
- 在邻接表中只须对每个边表中的结点个数计数便可确定。当时,使用邻接表计算边的数目,可以节省计算时间。
-
-
图的遍历
-
深度优先
-
邻接矩阵
void DFS(int x){ cout<<graph.vex[x]<<" "; vis[x] = 1; for(int i=0;i<n;i++) if(graph.arcs[x][i] && !vis[i]) DFS(i); } -
邻接表
void DFS(int x){ cout<<vexnode[x].vex<<" "; vis[x] = 1; edgenode *tmp=vexnode[x].link; while(!tmp){ if(!vis[tmp->adjvex]) DFS(tmp->adjvex); tmp=tmp->next; } }
-
-
广度优先
-
邻接矩阵
void BFS(int x){ cout<<graph.vex[x]<<" "; vis[x] = 1; q.push(x); while(!q.empty()){ int tmp=q.front();q.pop(); cout<<graph.vex[tmp]<<" "; vis[tmp]=1; for(int i=0;i<n;i++) if(graph.arcs[tmp][i] && !vis[i]) q.push(i); } } -
邻接
void BFS(int x){ q.push(x); while(!q.empty()){ int tmp=q.front(); q.pop(); cout<<vexnode[tmp].vex<<" "; vis[tmp] = 1; edgenode *tmmp=vexnode[tmp].link; while(tmmp){ if(!vis[tmmp->adjvex]) q.push(tmmp->adjvex) tmmp=tmmp->next; } } }
-
-
-
图的应用:
-
解决网络环路问题(生成树;最小生成树)
-
Prime:
Prime的核心是点,要求n-1个边把n个点连起来。没加入一个边,更新点到剩下点的最短距离。
#include<bits/stdc++.h> #define MAXN 1005 #define MAXM 1005 using namespace std; int n, m; typedef struct { char vex[MAXN]; int arcs[MAXN][MAXN]; } graph; graph mapp; typedef struct{ int from_vex, end_vex; double value; } edge; edge T[MAXN]; void init(){ memset(mapp.arcs, 0x7f, sizeof(mapp.arcs)); } void Creat() { for (int i = 0; i < n; i++) cin >> mapp.vex[i]; for (int i = 0; i < m; i++) { int x, y, w; cin >> x >> y >> w; //无向图 w=1 mapp.arcs[x][y] = mapp.arcs[y][x] = w; //无向图 mapp.arcs[x][y] = w; //有向图 } } void Prime(int x){ for(int i=0;i<n-1;i++){ T[i].from_vex = x; if(i>=x){ T[i].end_vex = i+1; T[i].value = mapp.arcs[x][i+1]; } else{ T[i].end_vex = i; T[i].value = mapp.arcs[x][i]; } } for(int i=0;i<n-1;i++){ int min = 0x7f7f7f7f, m=-1; for(int j=i;j<n-1;j++){ if(T[j].value < min){ min = T[j].value; m=j; } } edge tmp; tmp = T[i]; T[i] = T[m]; T[m] = tmp; int end = T[i].end_vex; for (int j = i + 1; j < n - 1; j++) { if (mapp.arcs[end][T[j].end_vex] < T[j].value) { T[j].from_vex = end; T[j].value = mapp.arcs[end][T[j].end_vex]; } } } } int main(){ init(); cin>>n>>m; Creat(); Prime(0); int values = 0; for(int i=0;i<n-1;i++) values+=T[i].value; cout<<values; } -
Kruskal
Kruskal的核心是边,每次选最短的并检查是否成环,核心还是贪心算法
#include <bits/stdc++.h> #define MAXN 1005 #define MAXM 1005 using namespace std; int n, m; typedef struct { int from_vex, end_vex; int value; int sign; } edge; edge T[MAXM]; int node[MAXN]; void init() { cin >> n >> m; for (int i = 0; i < n; i++) node[i] = i; for (int i = 0; i < m; i++) { cin >> T[i].from_vex >> T[i].end_vex >> T[i].value; } } void kruskal() { for (int i = 0; i < n - 1;) { int minn = 0x7fffffff, minx = -1; for (int j = 0; j < m; j++) { if (T[j].value < minn && T[j].sign==0) minn = T[j].value, minx = j; } T[minx].sign = 1; if (node[T[minx].end_vex] == node[T[minx].from_vex]) T[minx].sign = 2; else { i++; int temp = node[T[minx].end_vex]; for (int j = 0; j < n; j++) if (node[j] == temp) node[j] = node[T[minx].from_vex]; } } } int main() { init(); kruskal(); int values = 0; cout<<"Deg:\n"; for(int i=0;i<n;i++) cout<<node[i]<<" "; cout<<"\nREl:\n"; for (int i = 0; i < m; i++) if (T[i].sign == 1){ cout<<T[i].from_vex<<" "<<T[i].end_vex<<" "<<T[i].value<<endl; values += T[i].value; } cout << values; }
-
-
解决网络路由问题(最短路问题)
-
Floyd(多源最短路径)
#include<bits/stdc++.h> #define MAXN 1005 using namespace std; typedef struct { int n, m; int map[MAXN][MAXN]; }graph; graph mapp; int path[MAXN][MAXN]; void Floyd(){ for(int k=0;k<mapp.n;k++) for (int i = 0; i < mapp.n; i++) for (int j = 0; j < mapp.n; j++){ long long tmp = mapp.map[i][k]; tmp += mapp.map[k][j]; long long tmmp = mapp.map[i][j] ; if (tmmp > tmp) { mapp.map[i][j] = tmp; path[i][j] = path[k][j]; } } for(int i=0;i<mapp.n;i++) for(int j=0;j<mapp.n;j++){ cout<<mapp.map[i][j]<<": "<<i; int pre = path[i][j]; while(pre!=0 && pre!=i+1){ cout<<"->"<<pre-1; pre = path[i][pre-1]; } cout << "->" << j<<"\n"; } } void init(){ cin>>mapp.n>>mapp.m; memset(mapp.map, 0x7f, sizeof(mapp.map)); for(int i=0;i<mapp.m;i++){ int x, y, z; cin>>x>>y>>z; mapp.map[x][y] = mapp.map[y][x] = z; path[x][y] = x+1; } } int main(){ init(); Floyd(); } -
Dijkstra(单源最短路径)
#include <bits/stdc++.h> #define MAXN 1005 using namespace std; typedef struct { int n, m; int map[MAXN][MAXN]; } graph; graph mapp; int dist[MAXN], path[MAXN]; bool s[MAXN]; void init() { cin >> mapp.n >> mapp.m; memset(mapp.map, 0x7f, sizeof(mapp.map)); for (int i = 0; i < mapp.m; i++) { int x, y, z; cin >> x >> y >> z; mapp.map[x][y] = z; // mapp.map[x][y] = mapp.map[y][x] = z; } for (int i = 0; i < mapp.n; i++) mapp.map[i][i] = 0; } void Dijkstra(int x) { for(int i=0;i<mapp.n;i++){ dist[i] = mapp.map[x][i]; if(dist[i]!=mapp.map[0][0]) path[i] = x+1; } s[x] = 1; for (int i = 0; i < mapp.n-1; i++) { int minx = 0x7fffffff, k=-1; for (int j = 0; j < mapp.n; j++) { if(s[j]==0 && dist[j]<minx){ minx = dist[j]; k=j; } } s[k] = 1; for (int j = 0; j < mapp.n; j++) { long long tmp = dist[k]; tmp += mapp.map[k][j]; if (s[j] == 0 && dist[j] > tmp) { dist[j] = dist[k] + mapp.map[k][j]; path[j] = k+1; } } } for (int i = 0; i < mapp.n; i++){ cout << dist[i] << ": " << x; int pre = path[i]; while (pre != 0 && pre != x + 1) { cout << "->" << pre - 1; pre = path[pre - 1]; } cout << "->" << i << "\n"; } } int main() { init(); Dijkstra(0); }
-
-
项目进度安排问题
-
拓扑排序
-
拓扑排序:
-
按一定顺序进行的活动,可以使用顶点表示活动,顶点之间的有向边表示活动间的先后关系的有向图来表示,这种有向图称为顶点表示活动网络(Activity On Vertex network)简称AOV网。
-
限制活动只能串行进行,将AOV网中的所有顶点排列成一个线性序列vi1,vi2,…,vin,并且这个序列同时满足关系:若在AOV网中从顶点vi到顶点vj存在一条路径,则在线性序列中vi必在vj之前,称这个线性序列为拓扑序列。把对AOV网构造拓扑序列的操作称为拓扑排序。
#include<bits/stdc++.h> #define MAXN 1005 using namespace std; struct mapp{ int n, m; int map[MAXN][MAXN]; }graph; typedef struct node { int adjvex; int value; node *next; } edgenode; typedef struct { char vex; int in; edgenode *link; } vexnode; vexnode ga[MAXN]; int n, m; void init1() { cin>>graph.n>>graph.m; for(int i=0;i<graph.m;i++){ int x, y, z; cin>>x>>y>>z; graph.map[x][y]=z; } } void TopoSort1(){ // 邻接矩阵实现 bool vis[graph.n]; memset(vis, 0, sizeof(vis)); int cnt=0; for(int i=0;i<graph.n;i++){ int emp=-1; for(int j=0;j<graph.n;j++){ if(vis[j]==0){ int tmp=0; for(int k=0;k<graph.n;k++) tmp = tmp|graph.map[k][j]; if(tmp==0){ emp = j; break; } } } if(emp==-1) break; else{ vis[emp] = 1; cnt++; cout<<emp<<" "; for(int j=0;j<graph.n;j++) graph.map[emp][j]=0; } } if(cnt!=graph.n) cout<<"Error!!!"; } void init2() { cin >> n >> m; for (int i = 0; i < n; i++) { char tmp; cin >> tmp; ga[i].vex = tmp; ga[i].link = NULL; } for (int i = 0; i < m; i++) { int x, y, z; cin >> x >> y >> z; ga[y].in++; edgenode *tmp = (edgenode *)malloc(sizeof(edgenode)); tmp->adjvex = y; tmp->next = NULL; tmp->value = z; tmp->next = ga[x].link; ga[x].link = tmp; } } void TopoSort2() { int cnt = 0, tmp = -1; stack<int> st; for (int i = 0; i < n; i++) if (ga[i].in == 0) { st.push(i); } while (!st.empty()) { int x = st.top(); st.pop(); cout << x << " "; cnt++; edgenode *tmp = ga[x].link; while (tmp != NULL) { ga[tmp->adjvex].in--; if (ga[tmp->adjvex].in == 0) st.push(tmp->adjvex); tmp = tmp->next; } } if (cnt < n) cout << "ERROR!"; // if(tmp==-1 && cnt!=n) // cout<<"ERROR!!!"; } int main(){ init2(); TopoSort2(); }
-
-
-
关键路径
-
-
散列结构与索引技术
索引结构
-
概念:
索引结构包括两部分:索引表和数据表。
- 索引表:指明结点与其存储位置之间的对应关系的表。索引表中的每一项称作索引项,索引项的一般形式是:(关键字,地址)。其中关键字是能唯一标识一个结点的那些数据项。
- 数据表:存储结点信息的,索引结构中常用的数据表是线性表。
-
查找:
-
顺序查找
-
二分查找
-
分块查找
-
索引表,因为索引表是有序表,故可采用顺序查找或折半查找,以确定待查找的记录在哪一块;
-
在已确定的那一块中进行顺序查找。
说明:由于分块查找实际上是两次查找过程,故分块查找的算法即为这两种算法的简单合成,而整个算法的平均查找长度,即是两次查找的平均查找长度之和。
-
构造:
- 将数据表均分成块,前块中记录个数为 ,第块的记录数小于等于;
- 前一块中的最大关键字必须小于后一块中的最小关键字,即要求表是“分块有序”的;
- 抽取各块中的最大关键字及各块的起始位置构成一个索引表,即中存放着第块的最大关键字及该块在表中的起始位置。由于表是分块有序的,所以索引表是递增有序表
-
-
线性索引
- 稠密索引:对于索引非顺序结构,由于数据表中的记录是无序的,则必须为每个记录建立一个索引项,这种一个索引项对应数据表中一个对象的索引结构称为稠密索引;索引项中的地址将指出结点所在的存储位置
- 稀疏索引:对于索引顺序结构,由于数据表中的记录按关键字有序,则可对一组记录建立一个索引项,这种索引称为稀疏索引;索引项中的地址指出的则是一组结点的起始存储位置
倒排表
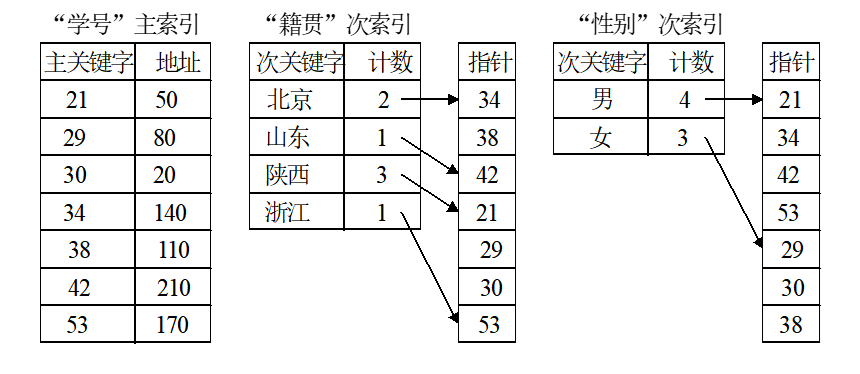
- 概念:
- 倒排表:可以把一些经常查询的属性设定为次关键字,并针对每一个次关键字属性,建立一个称为次索引的索引表:列出该属性的所有取值,并对每一个取值建立有序链表,并按存放地址递增的顺序或按关键字递增的顺序链接在一起。
- 倒排表是一种次索引的实现。在倒排表中所有次关键字的链都保存在次索引中,仅通过搜索次索引就能找到所有具有相同属性值的记录。
- 查找:倒排表查找是,先通过搜索次索引以确定该记录的主关键字,再通过搜索主索引确定记录的存放地址。这样在记录的存放地址发生变化时,只需修改主索引,次索引可以不用改动
多级索引
多级索引是一种静态结构,各级索引均为顺序表,每次修改都要重组索引。因此,当数据表在使用过程中记录变动较多时,应采用动态索引,例如二叉排序树,它本身是层次结构,无需建立多级索引,而且建立索引表的过程即排序过程。
散列技术
-
个人理解
散列技术就是利用一个函数建立key与addr(offset)的关系,便于查找。在建立索引的过程中耗费时间的点就是key向addr的转化,所以,为了效率,我们选取的散列函数要简单;我们希望key与addr建立一一对应关系,这里我们可以将key和addr视为一个映射,那么我们就要尽量满足唯一性。但唯一性是终归避免不了的,所以这里我们就需要其他的办法来帮忙解决。
-
概念:
- 以结点的关键字k为自变量,通过一个确定的函数关系f,计算出对应的函数值,把这个值解释为结点的存储地址,将结点存入f(k)所指的存储位置上。该方法称为散列法;又称关键字——地址转换法。
- 用散列法存储的线性表叫散列表(Hush Table)或哈希表。
- 函数f()称为散列函数或哈希函数,f(k)的值则称为散列地址或哈希地址。
- 通常散列表的存储空间是一个一维数组,散列地址是数组的下标,在不致于混淆之处,我们将这个一维数组空间就简称为散列表。
-
散列函数的选择:
-
数字选择法:
选取数字分布比较均匀的若干位作为散列地址
- key值数据位数比散列表地址多
- key值各位可知,与所有key各个位置上值的分布
-
随机数法:
以key为种子,生成的随机数为散列地址
1.关键字长度不等时采用此法构造散列地址较恰当
-
平方取中法:
先通过关键字的平方值扩大差别,再用数字选择法
- 与数据选择法情况基本一致,但各位分布不均匀
-
除留余数法:
选择适当的正整数p,用p去除关键字,取所得余数作为散列地址选择适当的正整数p,用p去除关键字,取所得余数作为散列地址
- 一般地选p为小于或等于散列表长度m的某个最大素数
-
折叠法:
将关键字分割成位数相同的几段(最后一段的位数可以不同),段的长度取决于散列表的地址位数,然后将各段的叠加和(舍去进位)作为散列地址。折叠法又分移位叠加和边界叠加两种。移位叠加是将各段的最低位对齐,然后相加;边界叠加则是两个相邻的段沿边界来回折叠,然后对齐相加
- 关键字位数较多
-
基数转换法
把关键字看成是另一个进制上的数后,再把它转换成原来进制上的数,取其中的若干位作为散列地址。一般取大于原来基数的数作为转换的基数,并且两个基数要互素
-
-
散列函数冲突
-
探查:
-
线性探查法
挨个看
-
二次探查法
发生冲突时,将同义词来回散列在第一个地址的两端
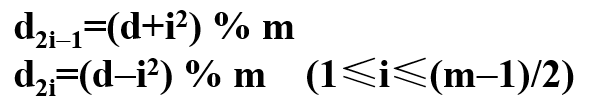
-
随机探查法
生成一个随机数,然后从随机数开始挨个看
-
-
解决:
-
开放地址法
当发生冲突时,使用某种方法在散列表中形成一个探查序列,沿着此序列逐个单元进行查找,直到找到一个空的单元时将新结点放入。
-
拉链法
将所有关键字为同义词的结点链接到同一个单链表中。若选定的散列函数的值域为0到m-1,则可将散列表定义为一个由m个头指针组成的指针数组HTP[m],凡是散列地址为i的结点,均插入到以HTP[i]为头指针的单链表中
-
-
博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议


