程序混淆综述

程序混淆综述
尝试开始学习代码混淆保护的相关内容,找到了一篇《A Taxonomy of Obfuscating Transformations》,名字是分类,但是各个方面蛮全的,就当综述来看了,包含了程序混淆的初衷、混淆的分类、构建一个混淆器的算法、反混淆器的基本算法、反混淆的算法(这里只是一个大概,还需要自己扩充)。
好多东西都是第一次接触,看的比较困难,花了很长时间。希望看的下一篇不会花费这么长的时间。
首先描述一个场景,Alice是一个小型软件开发人员,她希望通过Internet向用户提供她的应用程序,大概是收费的。Bob是Alice的竞争对手,他认为如果能访问Alice应用程序的关键算法和数据结构,他就能获得比Alice更大的商业优势。
也就是说两者存在这样一组关系:软件开发人员(Alice)试图保护她的代码不受攻击,反向工程师(Bob)的任务是分析应用程序并将其转换成易于阅读和理解的形式。这里需要注意的是,Bob没有必要将应用程序转换回源代码;Bob需要做的就是让Bob和他的程序员能够理解反向工程代码。还请注意,Alice没有必要保护整个应用程序,仅需要保护核心代码(数据结果与算法)。
-
可以使用法律或技术保护代码免受攻击。虽然版权法确实涵盖了软件制品,但经济现实使得像Alice这样的小公司很难执行法律来对抗更大更强大的竞争对手;
-
服务侧运行,将代码或者项目在服务端运行,并不分发给用户。缺点是,由于网络带宽和延迟的限制,应用程序的性能将比在用户站点本地运行时差得多。这里可以改进一下,仅将需要保护的代码放在服务端执行,其余部分依然分发给用户;
-
程序加密,将程序在分发给用户之前加密。但如果代码是由虚拟机解释器在软件中执行的,那么Bob一定可以拦截并反编译解密的代码;
-
代码混淆,通过一个混淆器来运行她的应用程序,这个程序将应用程序转换成一个在功能上与原始应用程序相同的程序,但对Bob来说,新的程序更加难以理解。
但只要有足够的时间和决心,Bob总是能够剖析Alice的应用程序以检索其重要的算法和数据结构,只是付出与收获需要进行权衡(这里有点像之前学密码的时候讲得,只要在一定资源内安全就可以了)。
代码混淆
混淆是指将应用转换成更难以理解和逆向工程的等价程序,目的是保护代码不被窥探。一般用于知识产权保护Intellectual Property,数字版权管理Digital Rights Management以及在软件中隐藏恶意行为。一般来说,混淆可以保护关键的(通常是小的)代码部分不被逆向工程分析与破坏。
定义
首先将代码混淆进行形式化定义: 我们设定为源程序,为混淆后的程序,那么混淆即可表示为,我们要求与可观测到的行为一致:
- 如果终止失败或带错误条件终止,那么可能终止,也可能不终止。
- 其余情况下,与的输出相同 这里可观测行为是指用户体验到的行为或者情况(输入输出、停止服务、特定报错等)。也因此,可能具有不具有的功能(例如闯进文件,通过网络传输信息等)。这里也并没有并没有要求和相等,一般来说比慢或者使用更多的内存。
分类
根据图一,可以将混淆技术详细分类如下:
布局混淆(Layout obfuscation)
这类混淆针对源代码的布局,例如:
-
formatting changes:代码格式修改
-
comment removal:删除注释
-
identifier scrambling:变量和方法名称乱序
均是
one-way、free、low potency,但是identifier scrambling比formatting changes与comment removal更加有效,因为identifier name含有更多的语义信息。
控制流混淆(Control obfuscation)
这类混淆针对程序控制流进行转换,以隐藏程序真实控制流。可以分为:
-
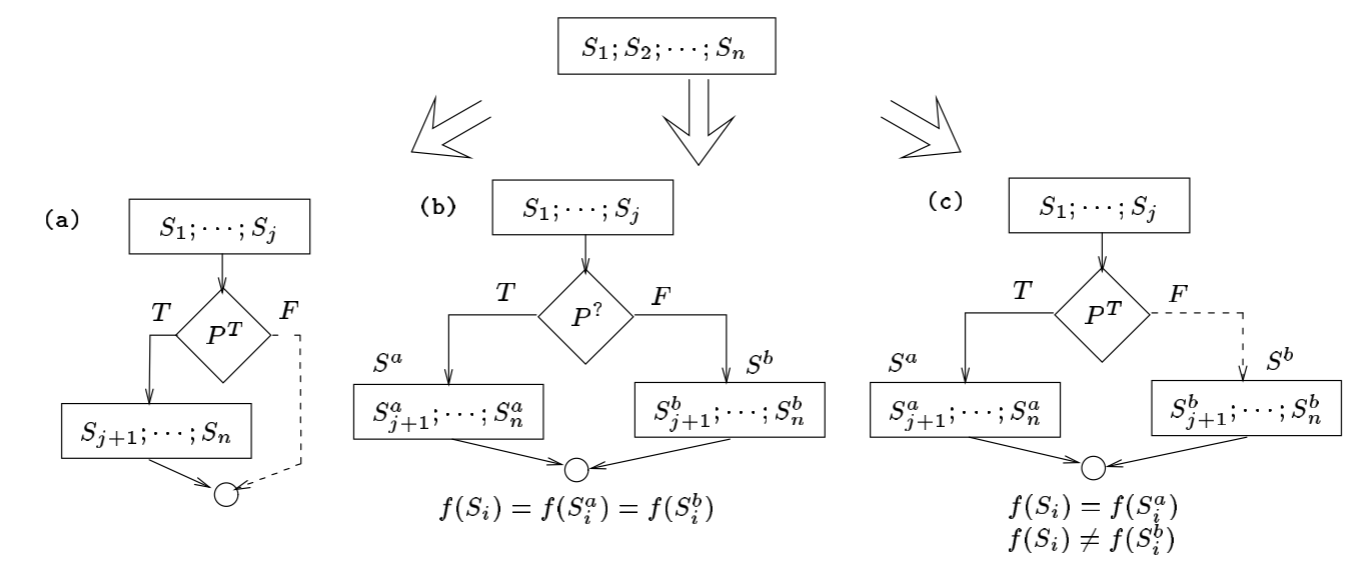
计算(Computations):插入无关代码、扩展循环条件、控制流约减等
- 将实际的控制流隐藏在对实际的计算没有影响的语句后面;
- 在目标代码级别引入没有相应高级语言结构的代码序列;
- 移除实际的控制流抽象,或者引入虚假的控制流抽象
- 插入无关代码 Insert Dead or Irrelevant Code
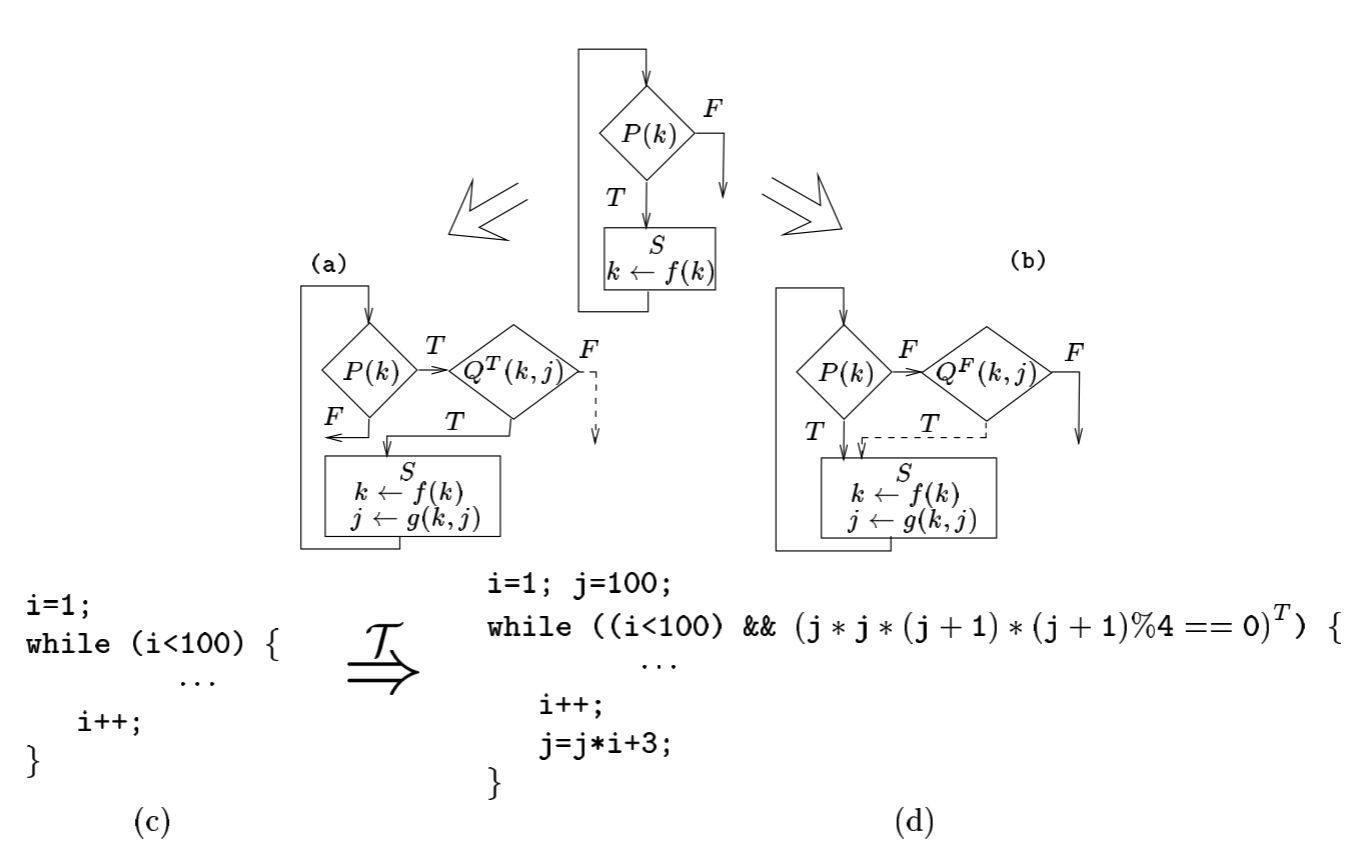
- 扩展循环条件 Extend Loop Conditions
- 控制流约减 Convert a Reducible to a Non-Reducible Flow Graph
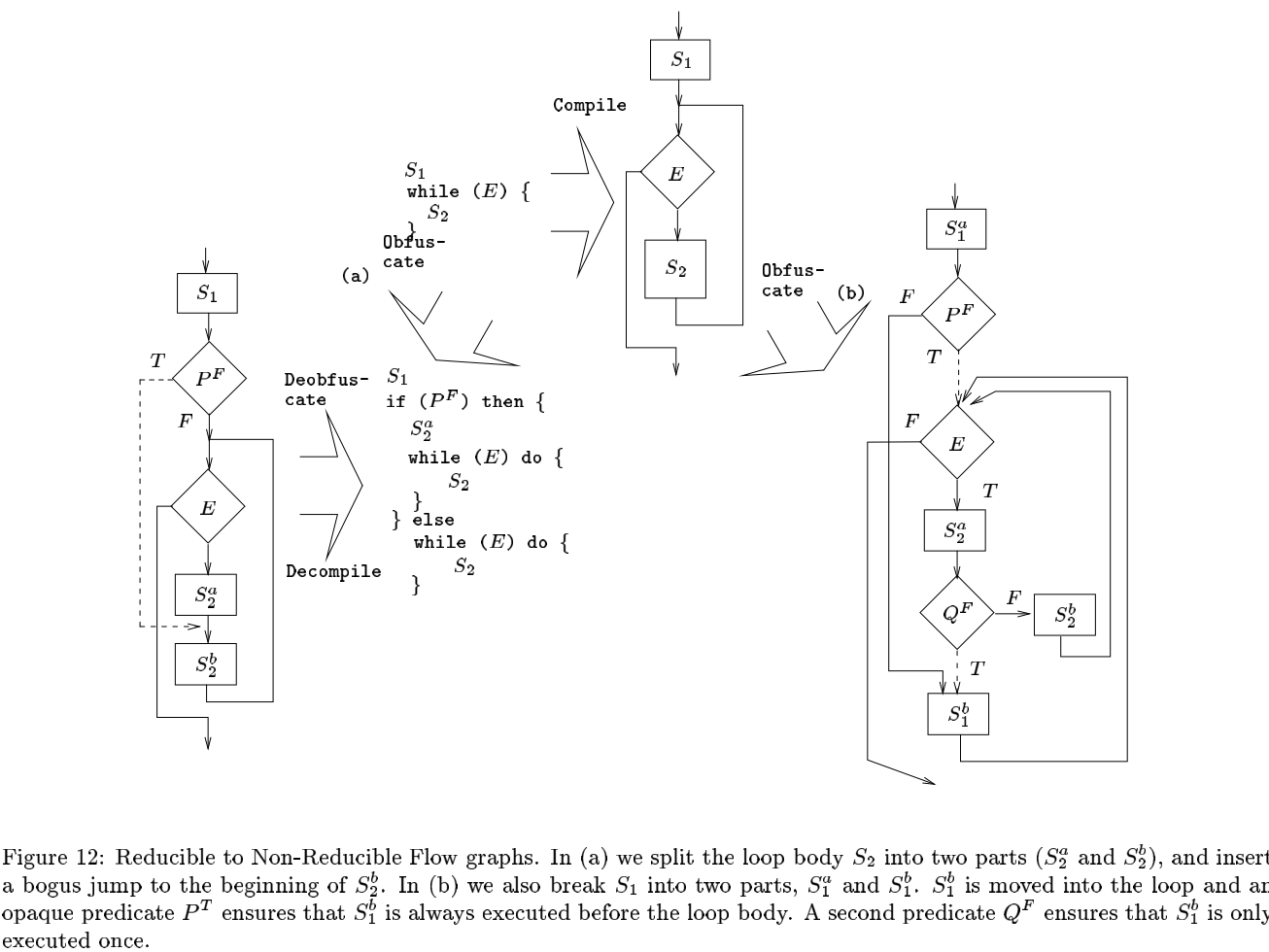
-
删除库调用和编程习惯用法 Remove Library Calls and Programming Idioms
通过自行构建函数调用库,来隐藏调用的库与函数名称。或者将常用的数据结构转换为不常用的数据结构进行混淆。
-
表解释 Table Interpretation
个人理解就是虚拟机保护,构建一个虚拟机,然后再将指令转换为虚拟机指令
-
添加冗余操作数 Add Redundant Operands
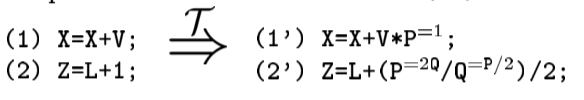
-
代码并行化 Parallelize Code
- 插入无用虚拟过程
- 我们可以将应用程序代码的一个连续部分分割成多个并行执行的部分(无数据依赖,直接转化;有数据依赖,通过await、advance等控制顺序)
-
聚合(Aggregation):内联、划线、交织、克隆方法、循环展开等
- 将一个方法的代码(逻辑上具有连贯性)分解分散到程序中去;
- 将不属于一个方法的代码聚合成一个方法。
-
内联和大纲方法 Inline and Outline Methods
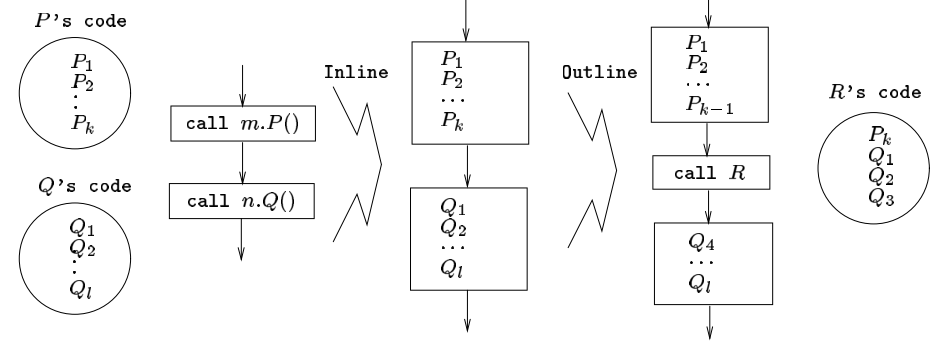
-
交错方法 Interleave Methods

-
克隆方法 Clone Methods

-
循环转化

-
排序(Ordering):语句、循环、表达式乱序等
将逻辑上关联的语句在编码上不关联
例如:随机调整基本块内语句顺序,破坏程序员的源代码局部性假设。
数据流混淆(Data obfuscation)
这类混淆针对程序的数据进行转换,以隐藏数据结构。可以分为:
-
存储与编码(Storage & Encoding):改变变量编码、提升标量、变量拆分、将变量提升为对象、静态数据动态生成、变量生命周期改变等
- 改变变量编码
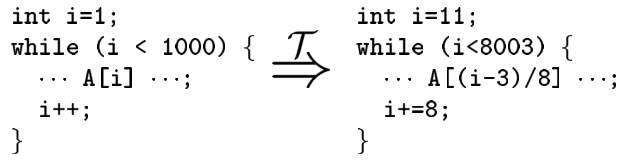
-
提升标量
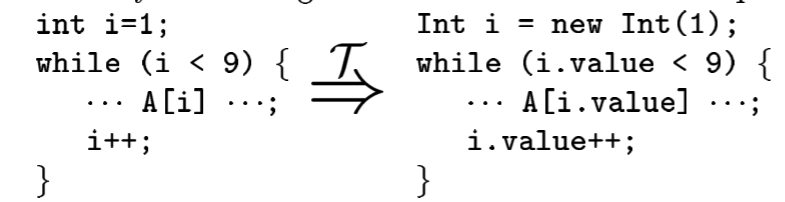
-
改变变量生命周期
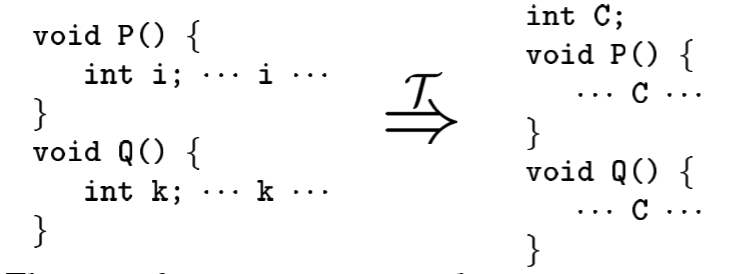
-
变量拆分
将一个类型的变量分割为个类型的变量,需要提供以下三点:
- 将变量转化为变量的函数
- 将变量转化为变量的函数
- 将变量的运算映射到变量的 运算
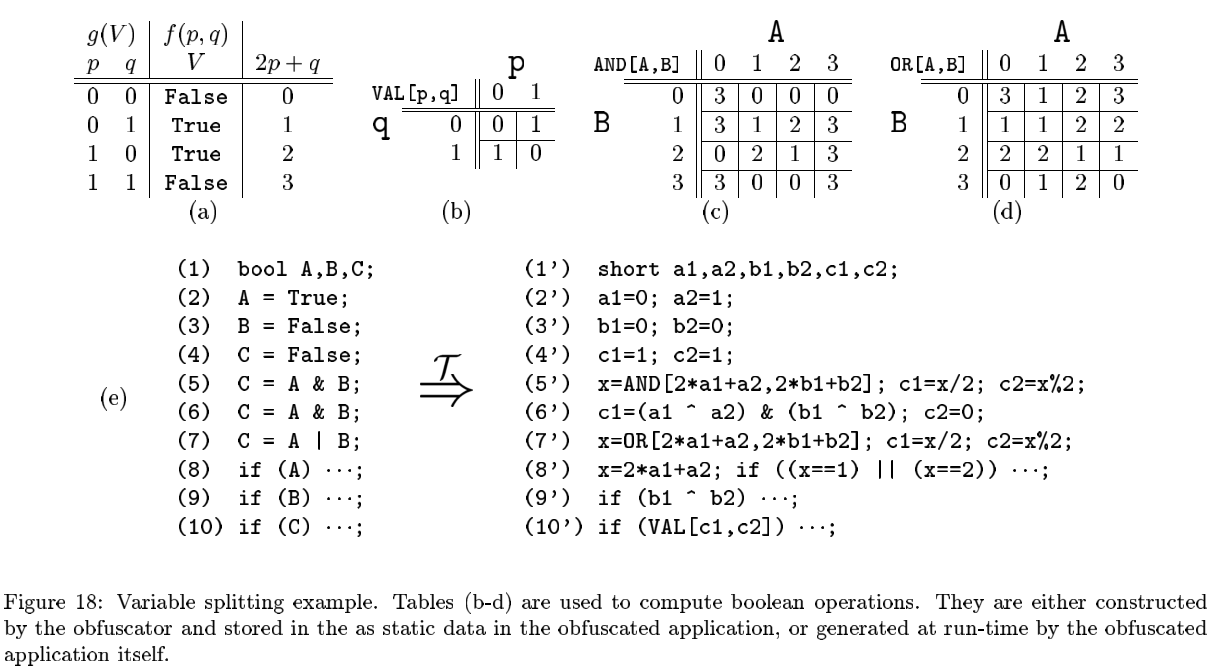
-
将静态变量动态生成
将字符串等静态变量,通过函数动态的生成。

-
聚合(Aggregation):合并标量、重构数组、修改继承等
-
合并变量
与变量拆分类似,区别是合并后的变量需要符合合并前的变量精度。

-
重构数组
拆分、合并、折叠、展平

-
修改继承
首先明确一点,类就是属性和方法的聚合,那么类的拆分就是:类的属性和方法是两个类()的属性和方法的并集。
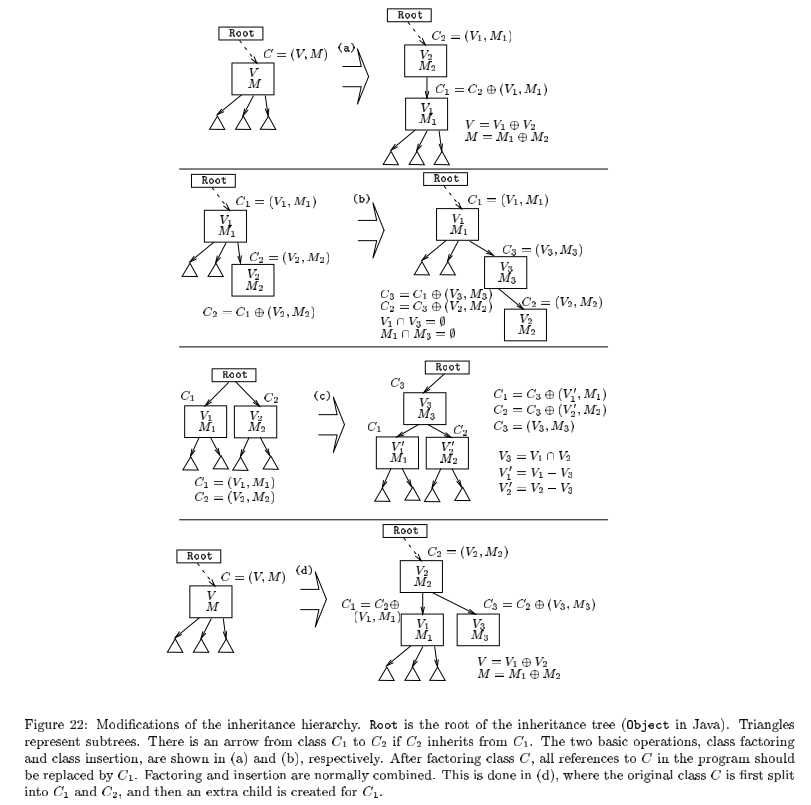
-
-
排序(Ordering):变量、数组元素、方法乱序
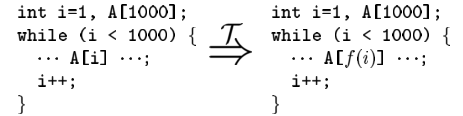
通过函数将对数组的操作乱序。
防范性混淆(Preventive obfuscation)
我们可以针对反混淆器进行特定的混淆,用来抵御反混淆工具的自动化分析,可以分为:
-
固有的(Inherent):增加额外依赖等
例如:添加无用的变量依赖关系,增加程序切片难度。
-
针对性的(Targeted):利用反混淆工具漏洞
例如:插入特定代码序列导致反混淆工具崩溃。
-
不透明构造(Opaque constructs)
这不是一类混淆,而是一种关键技术,用于创建难以推断值的不透明变量和谓词,从而实现强大的控制流混淆。详细定义为:
- 对于一个变量,如果该变量的某一个属性在混淆代码的点处是知道的,则该变量是不透明的,记为
- 对于一个谓词,如果该变量的输出在混淆代码的点处是已知的(对于混淆器或者编写混淆器的人来说),则该谓词是不透明的。如果谓词的输出永远为真,则记为;如果谓词的输出永远为假,则记为;如果谓词的输出有时为真有时为假 ,就记为
由于不透明谓词的构建事控制流混淆的核心部分,因此不透明谓词的质量就决定着混淆的质量。理论上,我们对不透明谓词设计的目标是“多项式时间构造,指数时间破解”。
无效的不透明谓词构造:

有效的不透明谓词构造:
-
使用对象别名创建不透明构造:
由于
precise static alias analysis是NP-Hard问题(甚至无法分析),因此通过该方法构建的不透明谓词是有效的。 -
使用多线程创建强韧度高的不透明构造
由于多线程执行顺序待定,因此对于一个多线程序列,有种执行顺序,因此对于该多线程序列的分析所需时间也是。
评价指标
有效性Potency:相较于原程序,混淆后的程序有多么更加难以理解
在混淆: 中,我们设定为源程序,为混淆后的程序,是一个满足定义的转化。设表示程序的复杂度,那么
表示混淆转换的有效性。我们认为时是一个有效的转化。其中的衡量尺度可以是以下任意一种:
- 程序长度(Program Length, ):衡量程序中操作符和操作数的数量。程序长度越大,复杂度越高。
- 圈复杂度(Cyclomatic Complexity, ):衡量程序中谓词的数量。圈复杂度越高,复杂度越高。 (这里的圈个人理解为cpu的那个cycle?)
- 嵌套复杂度(Nesting Complexity, ):衡量程序中条件语句的嵌套层级。嵌套复杂度越高,复杂度越高。
- 数据流复杂度(Data Flow Complexity, ):衡量程序中基本块变量引用的数量。数据流复杂度越高,复杂度越高。
- Fan-in/Fan-out复杂度(Fan-in/Fan-out Complexity, ):衡量程序中函数的形式参数数量,以及函数读取或更新的全局数据结构的数量。Fan-in/Fan-out复杂度越高,复杂度越高。
- 数据结构复杂度(Data Structure Complexity, ):衡量程序中声明的静态数据结构的复杂性。标量变量的复杂性是常数,数组的复杂性随维度和元素类型的复杂性增加,记录的复杂性随字段数量和复杂性增加。
- 面向对象复杂度(OO Metric Complexity, ):衡量类的复杂性。类的复杂度随方法数量()、在继承树中的深度()、直接子类的数量()、与其他类的耦合度()、可以响应发送给该类对象的消息的方法数量()以及类的方法是否引用相同的实例变量()而增加
若是一个有效的混淆变化,他应该满足:
- 增加整个程序的大小并引入新的类和方法。
- 引入新的谓词,并增加条件和循环结构的嵌套级别。
- 增加方法参数和类间实例变量依赖关系的数量。
- 增加继承树的高度。
- 增加长期变量依赖。
抵抗性Resilience:使用自动化反混淆工具将混淆后的程序还原回原程序的难易程度
在混淆: 中,我们设定为源程序,为混淆后的程序,是一个满足定义的转化。那么为转化对程序的抵抗性。
当时表示,该转化得出的无法还原回。其余情况下,抵抗性定义如下:
其中,Programmer Effort表示构造一个能有效降低T效能的自动去混淆器所需的时间;Deobfuscator Effort:该自动去混淆器能有效降低T效能所需的执行时间和空间。
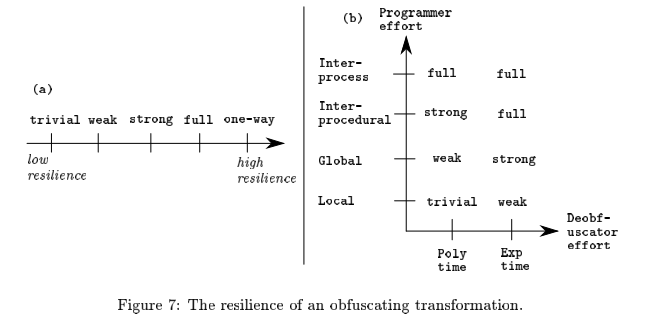
消耗Time/Space Cost:将原程序混淆所消耗的时间与空间成本
在混淆: 中,我们设定为源程序,为混淆后的程序,是一个满足定义的转化。那么表示相较于运行时所消耗额外的时间获空间:
质量Quality:一个转换的质量定义为其效果度、韧性和代价的组合
在混淆: 中,我们设定为源程序,为混淆后的程序,是一个满足定义的转化。那么表示该转化的质量,由上述三个属性联合定义:
混淆器算法
一般混淆器的算法大致如下所示:
while(!Done(A)){ // Done确定何时达到了所需的模糊程度
S = SelectCode(A); // 返回下一个要模糊处理的源代码对象
T = SelectTransform(S); // 返回应该用于模糊处理特定源代码对象的转换
A = Apply(T, S); // 将转换应用到源代码对象,并相应地更新应用程序
}
也就是说,对于所有的混淆器,都由上述算法中提及的几个算法组成:Done、SelectCode、SelectTransform、Apply。因此对于混淆器的分析、改进、设计都是从以上四个模块,以及四个模块内部的算法出发。
接下来做更为学术的规范。
Notation
首先做一下符号约定。
:代码对象S中使用的语言构造。描述开发者在开发中所使用的语言构造的集合。
:描述转化对代码对象的适用性。描述了一组映射,对于代码对象(),每一种转换方法()对其的使用程度(V)。
:代码对象S的混淆优先级。如果包含算法核心,那么便高;如果里面是一些不重要的代码,便低。
:模块M的执行时间顺序。
:对代码对象使用变化的抵抗性。
:对代码对象使用变化的有效性。
:对代码对象使用变化的花销。
:将转化与该转化将添加到程序中的构造集合映射起来。
Code Obfuscation(混淆器算法)
Input
- 一个由多个源码文件或源码对象文件组成的应用
- 标准库文件
- 一系列混淆变化
- 将转化与该转化将添加到程序中的构造集合映射起来的映射
- 对应中的组成的
- 两个数值
AcceptCost>0和ReqObf>0。AcceptCost是用户将接受的最大额外执行时间/空间惩罚的度量。ReqObf是对用户所需要的混淆程度的度量。
Output
由源代码或目标代码组成的模糊应用程序
Steps
-
加载应用程序中将被混淆的
- 如果这里的是源码文件,那么混淆器必须带有完整的编译器前端进行词法、语法、语义解析;
- 如果这里的是代码对象文件,且含有大部分或全部信息,这个方法更为推荐。
-
加载应用程序直接或间接引用的库文件
-
构建应用程序的内部表示。内部表示的选择取决于源语言的结构和混淆器实现的转换的复杂性。一组典型的数据结构可能包括:控制流图、调用图、类继承图
-
分别使用
Pragramatic Information算法构造映射和,使用Obfuscation Priority算法构造,使用Obfuscation Appropriateness算法构造。 -
将模糊处理转换应用到应用程序。在每一次循环中,我们选择一个要进行模糊处理的源代码对象和一个适用于的合适的转换。当达到了所需的模糊处理级别或超过了可接受的执行时间成本时,混淆器便会停止。
while(true){ S = SelectCode(I); T = SelectTransform(S, A); /* Apply T to S and update relevant data structures from point 3; */ if(Done(ReqObf, AcceptCost, S, T, I)) break; } -
将模糊处理的源代码对象重新构成一个新的模糊处理应用程序
SelectCode(代码选择算法)
Input
由Obfuscation Priority算法计算的模糊优先级映射
Output
一个源代码对象。计算所有源码对象的值,选择值最大的一个。
SelectTransform(转化选择算法)
Input
- 源码对象
- 由
Obfuscation Appropriateness算法计算的合适度映射
Output
变换
Steps
可以使用多种的启发式方法来选择最合适的转换,以应用于特定的源代码对象。但是注意的是,这里需要考虑到转换的有效性、抵抗性以及损耗。这里是一个例子:
其中是设定的常量,是中选定变化的有效度量。
Done(完成判断算法)
Input
ReqObf,剩余的模糊程度。AcceptCost,剩余的可接受的执行时间损耗。- 一个源代码对象
- 一个转换
- 代码对象混淆的优先级映射
Output
- 更新后的
ReqObf; - 更新的
AcceptCost; - 更新后的代码对象混淆的优先级映射;
- 是否已经到达结束条件
Step
Done函数不仅更新了代码对象的混淆优先级队列,还更新ReqObf和AcceptCost,并确定是否已达到终止条件。
Pragramatic Information(统计信息算法)
Input
-
一个应用
-
一组输入数据
Output
- 映射,对于中的每个模块,给出了的执行时间排序。
- 映射,对于中的每个源代码对象,给出了中使用的语言结构集合。
Steps
计算语用信息。此信息将用于为每个特定的源代码对象选择正确的转换类型。
-
计算动态语用信息。例如,运行应用程序在pro上的输入数据集,我提供的用户。为每个模块/基本块计算R(M) (M的执行时间排名),表示应用程序花费最多时间的位置。
-
计算静态语用信息。提供了程序员在中使用的各种语言结构的统计信息。
for S in A: O = set() # The set of operators that S uses C = set() # The set of high-level language constructs (WHILE statements, exceptions, threads, etc.) that S uses; L = set() # The set of library classes/routines that S references; P_S = O | C | L
Obfuscation Priority(混淆优先级算法)
Input
-
应用程序
-
模块的时间排序
Output
对于中的每个源代码对象的优先级映射
Steps
可以由用户显式提供,也可以根据Pragramatic Information算法中收集的统计数据进行启发式计算。可能的启发可能是:
- 对于中的任意常规的,设与成反比。也就是说,如果执行一个模块花费了很多时间,那么可能是一个重要的过程,应该被严重混淆。
- 设为的复杂度,由某个软件复杂度度量来定义。直观地说,某个模块运行时间越长,含有的信息越多。
Obfuscation Appropriateness(混淆合适度算法)
Input
-
一个应用程序
-
一个映射,对于每个转换,它给出了该转换将添加到应用程序的一组语言结构。
-
一个映射,对于中的每个源代码对象所使用的构造。
Output
映射,对于中的每个源代码对象和每个转换,它给出对于的合适度。
Steps
映射主要基于Pragramatic Information算法的结果计算得来。

反混淆
反混淆器
混淆的过程可以看作是将一个冗余的程序嵌入到我们想要保护的程序里面,然后由冗余程序将保护的程序隐藏在无关的代码之后。而不透明谓词是混淆器用来防止伪内部程序被轻易识别和删除的主要工具。因此,反混淆器的主要难点便是在解析推断不透明谓词,大致流程如下:

也因此,反混淆器的核心便是对不透明谓词进行识别与计算:
不透明谓词的识别
不透明谓词可以是局部的,全局的以及过程间的。分别举例说明:便是局部的,而便是全局的,而如果是分别在两个过程中计算的,那么便是过程间的。
对不透明谓词的识别可以通过以下方案:
-
通过模式匹配
-
原理:去混淆器可以将程序与已知的混淆器策略来识别不透明的谓词,一般适用于适用于简单的局部谓词。
-
应对:尽量减少使用封装好的混淆器,同时尽量选择与应用程序在语法上相似的不透明谓词结构。
-
-
通过程序切片
- 原理:通过使用程序切片,提取程序中关于不透明谓词变量的相关代码,来提取整个不透明谓词内容,即使不透明谓词的生成过程分散在整个程序之中。
- 应对:添加参数别名与变量的数据依赖,提高切片的成本。
-
通过统计分析
- 原理:通过对程序所有谓词进行监测,当程序的覆盖率达到一个高度且某谓词的结果一直一样,那么便可以提醒逆向工程师该谓词可能是不透明谓词。
- 应对:添加不确定谓词;让不透明谓词之间存在关联,即在计算一个的同时需要计算全部。
不透明谓词的计算
-
统计分析
尝试使用猜测的结果与谓词进行替换,当进行大量的尝试之后,如果与原来的输出一直相同,便认为该谓词为不透明谓词。但是该方法一是对我们的输入要求较高,需要充分覆盖程序中的所有路径;二是获取大量正确的输入/输出数据困难,尤其是应用程序的内部结构未知或输入来自GUI。
-
数据流分析
一般只能解决常数传播类型。
-
数论证明
通过数论证明验证不透明谓词的结果。
-
部分求值
Partial Evaluation(部分求值)是一种计算机科学中的编程技术,用于优化程序的执行。它的核心思想是将程序的一部分或全部在编译或运行时进行计算,以减少运行时的计算工作量。Partial Evaluation通常用于编译器优化和程序性能改进中。
Partial Evaluation的主要目标是减少程序的运行时间和内存消耗,通过将程序中的一些表达式或计算在编译或运行时预先计算出来,以减少重复的计算。这通常涉及到静态分析程序代码,找到可以在编译时确定值的表达式,并将它们替换为它们的计算结果。这个过程可以在多个阶段进行,每个阶段都可以进一步减少程序的复杂性和计算成本。
Partial Evaluation的一个典型应用是在编译器中,其中编译器可以通过分析程序的代码并进行部分求值来生成更高效的机器代码。这可以包括常量折叠、内联函数、死代码删除等优化技术。
总之,Partial Evaluation是一种用于优化程序性能的技术,通过在编译或运行时预先计算部分程序代码,以减少运行时计算的开销,从而提高程序的执行效率。
论文原文:去模糊处理也与部分求值有着惊人的相似之处。部分求值器将程序分为两部分:静态部分可以由部分求值器预先计算,动态部分在运行时执行。动态的部分将对应于我们原始的、不加掩饰的程序。
个人理解:在优化的过程中,如果部分求值求得是不透明谓词的话,那么这个部分求值的举动相当于是做了反混淆的工作。
很好理解,部分求值也对别名敏感,因此程序切片的应对措施也可以用在这里。

博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
本文永久链接是:http://example.com/2023/10/08/%E7%A8%8B%E5%BA%8F%E6%B7%B7%E6%B7%86%E7%BB%BC%E8%BF%B0/


